OpenAI and the road to text-guided image generation: DALL·E, CLIP, GLIDE, DALL·E 2 (unCLIP)

OpenAI recently announced their DALL·E 2 system capable of creating images based on a textual description. It’s the second version of the system, and the first one was published nearly a year ago. However, internally the model behind the DALL·E 2 is called unCLIP and it’s closer to OpenAI’s GLIDE system than to the original DALL·E.
The quality improvements are significant, and the examples published are awesome. Play with the demos in the original OpenAI blog post, look at the Instagram account, and Twitter hashtags #dalle and #dalle2. Only nearly 400 people have access to the system right now. Most of them are OpenAI employees or friends.
As for me, the DALL·E 2 system is a breakthrough comparable to AlphaGo by its impact. It looks like the model captures many difficult concepts and can combine them in a meaningful way. Just a couple of years ago, it was hard to predict that computers would be able to generate images from textual descriptions with such quality. Sam Altman mentioned in his blog post that our predictions about AI seem to be wrong and require updating as AI starts to impact creative work before physical labor.
Let’s look at the evolution of text-guided image generation models from OpenAI, as there are more data points than just the first and the second versions of DALL·E.
DALL·E evolution
DALL·E 1
Paper: https://arxiv.org/abs/2102.12092
Blog post: https://openai.com/blog/dall-e/
Code: https://github.com/openai/dall-e (it’s not complete and covers only the dVAE part)
Model: Not available
Alternative code (PyTorch): https://github.com/lucidrains/DALLE-pytorch Alternative code (JAX/Flax): https://github.com/borisdayma/dalle-mini
Alternative models (Russian): https://github.com/ai-forever/ru-dalle
The first version of DALL·E was a GPT-3 style transformer decoder that autoregressively generated a 256×256 image based on textual input and an optional beginning of the image.
You must have seen all these avocado chairs:

If you want to understand how a GPT-like transformer works, here is a great visual explanation by Jay Alammar.
Some technical details
A text is encoded by BPE-tokens (max. 256, you can play with GPT-3 tokenization here), and an image is encoded by special image tokens (1024 of them) produced by a discrete variational autoencoder (dVAE). dVAE encodes a 256×256 image into a grid of 32×32 tokens with a vocabulary of 8192 possible values. Because of the dVAE, some details and high-frequency features are lost in generated images, so some blurriness and smoothness are the features of the DALL·E-generated images.

The transformer is a large model with 12B parameters. It consisted of 64 sparse transformer blocks with a complicated set of attention mechanisms inside, consisting of 1) classical text-to-text masked attention, 2) image-to-text attention, and 3) image-to-image sparse attention. All three attention types are merged into a single attention operation. The model was trained on a dataset of 250M image-text pairs.

The trained model generated several samples (up to 512!) based on the text provided, then all these samples were ranked by a special model called CLIP, and the top-ranked one was chosen as the result of the model.

If you want a deeper explanation of how DALL·E works, here is a two-part introduction: part 1 and part 2.
CLIP
Paper: https://arxiv.org/abs/2103.00020
Blog post: https://openai.com/blog/clip/
Code: https://github.com/openai/CLIP (does not cover the training part)
Models: Available (on Apr 22, 2022, the last and the best ViT-L/14@336px model was published)
Alternative code: https://github.com/mlfoundations/open_clip (with training)
Alternative models (Multilingual): https://github.com/FreddeFrallan/Multilingual-CLIP
Alternative models (Russian): https://github.com/ai-forever/ru-clip
CLIP was originally a separate auxiliary model to rank the results from DALL·E. Its name is an abbreviation for Contrastive Language-Image Pre-Training.
The idea behind CLIP is simple. Let’s take a large dataset of image-text pairs scraped from the Internet (400M such pairs, and there was a poorly described part on how such dataset was collected). Then we train a contrastive model on such a dataset. Contrastive models produce high scores (similarity) for an image and a text from the same pair (so they are similar) and a low score for mismatched texts and images (and we hope that the chance is tiny that we get a good match between the current image and a text from any other pair in a training batch).
Some technical details
The model consists of two encoders: one for a text and another one for an image. Encoders produce embeddings (a multidimensional vector representation of an object, say 512 bytes for each). Then a dot product is calculated with two embeddings, and it results in a similarity score. Embeddings are normalized, so this procedure outputs cosine similarity. It is close to 1 for vectors pointing in the same direction (and consequently a small angle between them), 0 for orthogonal vectors, and -1 for opposite ones.
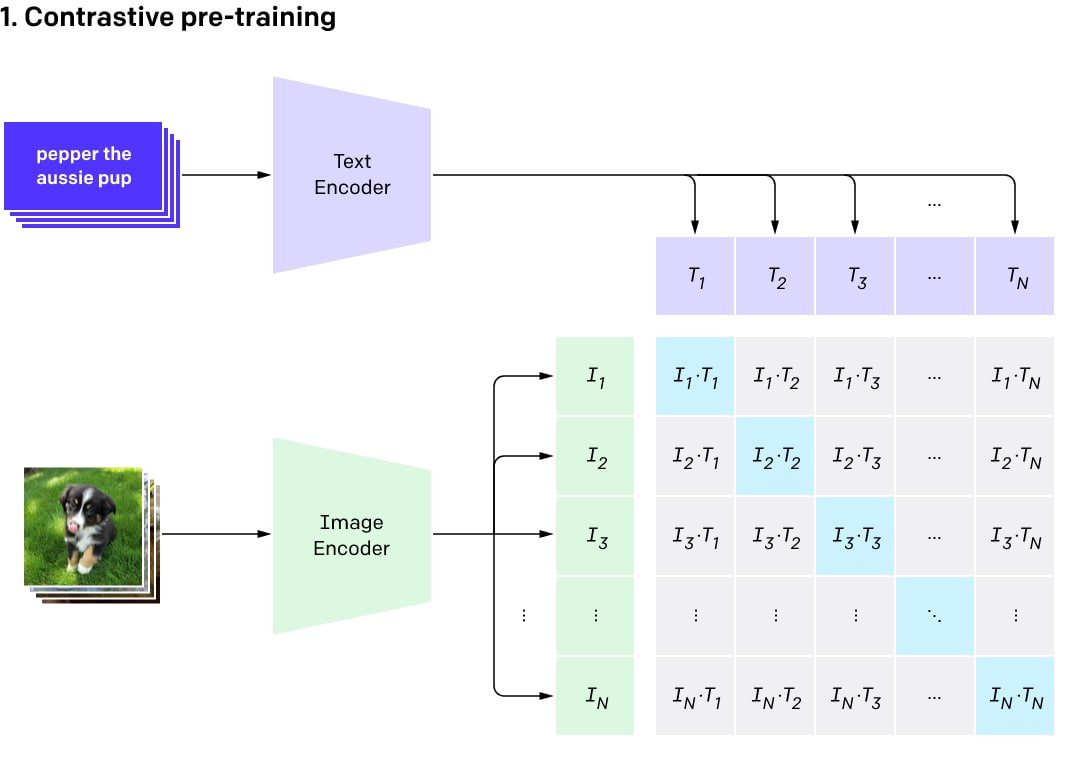
CLIP is a set of models. There are nine image encoders, five convolutional, and four transformer ones. Convolutional encoders are ResNet-50, ResNet-101 and EfficientNet-like models called RN50x4, RN50x16, RN50x64 (the higher numbers, the better the model). Transformer encoders are Vision Transformers (or ViT): ViT-B/32, ViT-B/16, ViT-L/14, and ViT-L/14@336. The last one was fine-tuned on images with a resolution of 336×336 pixels, and others were trained on 224×224 pixels.
OpenAI did their staged release procedure, with ViT-B/32 and ResNet-50 published the first, then came ResNet-101 and RN50x4, then RN50x16 and ViT-B/16 were published in July 2021, then came RN50x64 and ViT-L/14 in January 2022, and finally came ViT-L/14@336 in April 2022.
The text encoder is an ordinary transformer encoder but with masked attention. It consists of 12 layers with 8 attention heads each, with 63M parameters in total. Interestingly, the attention span is only 76 tokens (compared to the GPT-3 with 2048 tokens and a standard BERT with 512 tokens). So, the text part of the model is suitable for pretty short texts only, and you can’t put a large paragraph into the model. As DALL·E 2 uses mostly the same CLIP, it should have the same limitation.
After CLIP pre-training, you can use it for different tasks (a property of a good foundation model).
CLIP applications
Zeroth of all, you can use such a model for ranking text-image pairs as was done in DALL·E to score multiple results and choose the best one. Or you can use the CLIP features to train your custom classifiers on top of it. But there are more exciting cases.
Next, you can use CLIP for zero-shot classification (when you didn't specifically train the model to work with these classes) with any number of classes. The classes can be adjustable without retraining a model.
In a simple procedure, you create a dataset of text descriptions “a photo of a {object}” for a number of classes you want. Then you generate text embeddings for these descriptions and store them as vectors. When an image comes for classification, you generate an image embedding with the image encoder and calculate a dot product between the image embedding and all the precalculated text embeddings. You choose the pair with the highest score, and its corresponding class is the result.

It is zero-shot classification as you did not train your model for your particular set of classes at all (you might, if you want, and there were results for such a few-shot classification as well). You can now have an option to do prompt engineering (the same way you do it with GPT models) with a pretrained CLIP instead of training your classifiers from scratch or by fine-tuning pretrained image models.
The less obvious thing is that you can use CLIP to generate images (even if it wasn’t assumed to do it at all). Some good examples are CLIPDraw (Colab notebooks: #1, #2) and VQGAN-CLIP (Colab notebooks: #1, #2, more).
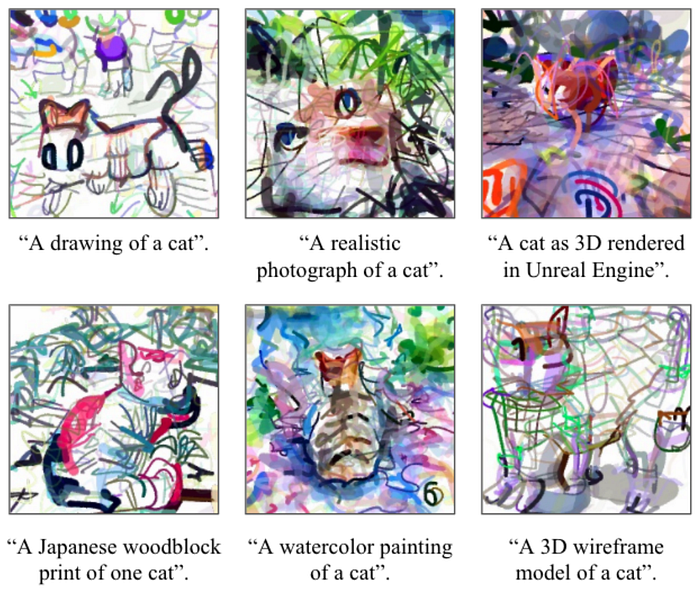

The procedure is simple and beautiful and significantly resembles the good old DeepDream. Start with a text description of the image you want and an initial image (random embedding, scene description in splines or pixels, anything else from which you can create an image in a differentiable way). Then run a loop of generating an image, adding some augmentations to improve stability, obtain CLIP embeddings for the resulting image and compare it with a CLIP embedding for the text describing an image. Calculate a loss based on this difference and run a gradient descent procedure to update the image to reduce the loss. After some iterations, you get the image well described with the text. The way how you create the initial scene (with splines, pixels, render primitives, latent codes from VQGAN, and so on) significantly influences the image characteristics.


CLIP embeddings do not capture everything, and there are interesting demonstrations of its weakness. One such well-known case is a typographic attack. In this attack, a text on an image can lead to the wrong classification of the image. You’ll see other weaknesses in a section dedicated to unCLIP.
There are alternative models with a similar structure as CLIP, say ALIGN from Google, or FILIP by Huawei.
GLIDE
Paper: https://arxiv.org/abs/2112.10741
Blog post: Strangely enough, OpenAI didn’t make a post on it
Code: https://github.com/openai/glide-text2im
Models: Available, but only a small model (300M instead of 3.5B parameters) trained on a filtered dataset (to prevent harmful uses).
GLIDE, which stands for Guided Language to Image Diffusion for Generation and Editing, is a text-guided image generation model by OpenAI that has beaten DALL·E, yet received comparatively little attention. It even has no dedicated post on the OpenAI site. GLIDE generates images with a 256×256 pixel resolution.
GLIDE model with 3.5B parameters (but it seems the correct number is 5B parameters as there is a separate upsampling model with 1.5B parameters) is favored over 12B parameters DALL·E by human evaluators and also has beaten DALL·E by FID score.

GLIDE models can also be fine-tuned to perform image inpainting, enabling powerful text-driven image editing, which is used in DALL·E 2.

GLIDE could be called DALL·E 2 at the moment it was published. Now when a separate DALL·E 2 system is announced (which is really called unCLIP inside the paper and heavily uses GLIDE itself), we may call GLIDE as DALL·E 1.5 :)
Some technical details
GLIDE resembles another kind of model called the diffusion model. In a few words, diffusion models add random noise to input data through the chain of diffusion steps, and then they learn to reverse the diffusion process to construct images from the noise.

Here is an excellent visual example of image generation with a diffusion model by Google and a post about it. Here is a great and profound introduction to diffusion models.

First, the authors trained a 3.5B parameter diffusion model that uses a text encoder to condition on natural language descriptions. Next, they compared two techniques for guiding diffusion models toward text prompts: CLIP guidance and classifier-free guidance (which produces better results).
Classifier guidance allows diffusion models to condition on a classifier’s labels, and gradients from the classifier are used to guide the sample towards the label.
The classifier-free guidance does not require a separate classifier model to be trained. is a form of guidance that interpolates between predictions from a diffusion model with and without labels.
As the authors state, classifier-free guidance has two appealing properties. First, it allows a single model to leverage its own knowledge during guidance, rather than relying on the knowledge of a separate (and sometimes smaller) classification model. Second, it simplifies guidance when conditioning on information that is difficult to predict with a classifier (such as text).
With CLIP guidance the classifier is replaced with a CLIP model. It uses the gradient of the dot product of the image and caption encodings with respect to the image.
In both classifier and CLIP guidance, we must train CLIP on noised images to obtain the correct gradient in the reverse diffusion process. Authors used CLIP models that were explicitly trained to be noise-aware, which are referred to as noised CLIP models. The public CLIP models, which have not been trained on noised images, can still be used to guide diffusion models, but the noised CLIP guidance performs favorably to this approach.
The text-conditioned diffusion model is an augmented ADM model architecture that predicts an image for the next diffusion step based on a noised image xₜ and corresponding text caption c.
The visual part is a modified U-Net architecture. The U-Net model uses a stack of residual layers and downsampling convolutions, followed by a stack of residual layers with upsampling convolutions, with skip connections connecting the layers with the same spatial size.

There are different modifications to the original U-Net architecture regarding width, depth, and so on. Global attention layers with several attention heads are added at the 8×8, 16×16, and 32×32 resolutions. Also, a projection of the timestep embedding was added to each residual block.
For the classifier guidance, a classifier architecture is the downsampling trunk of the U-Net model with an attention pool at the 8×8 layer to produce the final output.
The text is encoded into a sequence of K (the maximum attention span is unclear) tokens that passed through a transformer model.
The output of this transformer is used in two ways: first, the final token embedding is used in place of a class embedding in the ADM model; second,
the last layer of token embeddings (a sequence of K feature vectors) is separately projected to the dimensionality of each attention layer throughout the ADM model and then concatenated to the attention context at each layer.
The text transformer has 24 residual blocks of width 2048, resulting in roughly 1.2B parameters. The visual part of the model trained for 64×64 resolution consists of 2.3B parameters. In addition to the 3.5B parameters text-conditional diffusion model, the authors trained another 1.5B parameters text-conditional upsampling diffusion model to increase the resolution to 256×256 (this idea will be used in DALL·E as well). The upsampling model is conditioned on text in the same way as the base model but uses a smaller text encoder with a width of 1024 instead of 2048. For CLIP guidance, they also trained a noised 64×64 ViT-L CLIP model.
GLIDE was trained on the same dataset as DALL·E and the total training compute is roughly equal to that used to train DALL·E.
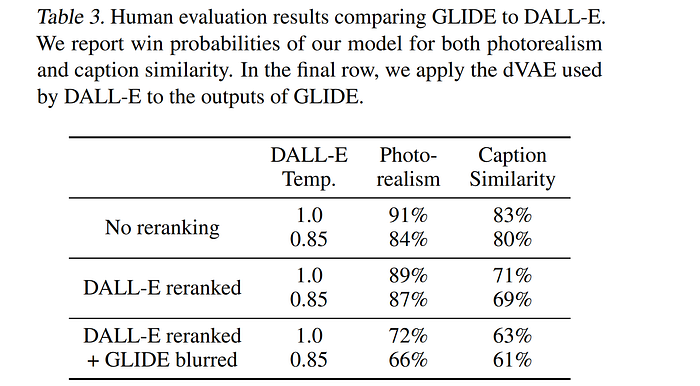
GLIDE is preferred by the human evaluators in all settings, even in the configurations that heavily favor DALL·E by allowing it to use a much larger amount of test-time compute (through CLIP reranking) while reducing GLIDE sample quality (through VAE blurring).
The model was fine-tuned to support unconditional image generation. This training procedure is exactly like pre-training, except 20% of text token sequences are replaced with the empty sequence. This way, the model retained its ability to generate text-conditional outputs, but can also generate images unconditionally.
The model was also explicitly fine-tuned to perform inpainting. During fine-tuning, random regions of training examples are erased, and the remaining portions are fed into the model along with a mask channel as additional conditioning information.
GLIDE can be used iteratively to produce a complex scene using a zero-shot generation followed by a series of inpainting edits.

and finally to move the wall up to the couch. The example from the original paper.
DALL·E 2/unCLIP
Paper: https://cdn.openai.com/papers/dall-e-2.pdf
Blog post: https://openai.com/dall-e-2/
Code: Not available
Models: Not available
Code (unofficial): https://github.com/lucidrains/DALLE2-pytorch
OpenAI announced its DALL·E 2 system on April 6th, 2022. The DALL·E 2 system significantly improves results over the original DALL·E. It generates images with 4x greater resolution (compared to original DALL·E and GLIDE), now up to 1024×1024 pixels. The model behind the DALL·E 2 system is called unCLIP.
The authors found that humans still slightly prefer GLIDE to unCLIP in terms of photorealism, but the gap is very small. Even with similar photorealism, unCLIP is strongly preferred over GLIDE in terms of diversity, highlighting one of its benefits. Remember, GLIDE itself was preferred over DALL·E 1 by a large margin, so DALL·E 2 significantly improves over its year-old predecessor, DALL·E 1.

in a field at sunrise in the style of Claude Monet”. Demo from the original blog post.
DALL·E 2 can combine concepts, attributes, and styles:

DALL·E 2 can also perform image editing based on text guidance, the feature present in GLIDE. It can add and remove elements while taking shadows, reflections, and textures into account:

DALL·E 2 can be used to generate variations of the original image:

There are some problems with DALL·E 2 as well.
In particular, unCLIP is worse at binding attributes to objects than a corresponding GLIDE model. For example, unCLIP struggles more than GLIDE with a prompt where it must bind two separate objects (cubes) to two separate attributes (colors):

unCLIP also struggles at producing coherent text:

Another issue is that unCLIP has a hard time producing details in complex scenes:

Some technical details
Many things changed internally. Now, it is a clever combination of CLIP and GLIDE, and the model itself (the full text-conditional image generation stack) is called unCLIP internally in the paper since it generates images by inverting the CLIP image encoder.
The model works the following way. The CLIP model is trained separately. Then the CLIP text encoder generates an embedding for the input text (caption). Then a special prior model generates an image embedding based on the text embedding. Then a diffusion decoder generates an image based on the image embedding. The decoder essentially inverts image embeddings back into images.

The CLIP model uses a ViT-H/16 image encoder that consumes 256×256 resolution images and has a width of 1280 with 32 Transformer blocks (it’s deeper than the largest ViT-L from the original CLIP work). The text encoder is a Transformer with a causal attention mask, with a width of 1024 and 24 Transformer blocks (the original CLIP model had 12 transformer blocks). It is unclear whether the text transformer attention span is the same (76 tokens) as in the original CLIP model.
The diffusion decoder is a modified GLIDE with 3.5B parameters. CLIP image embeddings are projected and added to the existing timestep embedding. CLIP embeddings are also projected into four extra tokens of context that are concatenated to the sequence of outputs from the GLIDE text encoder. The original GLIDE’s text conditioning pathway is retained because it could allow the diffusion model to learn aspects of natural language that CLIP fails to capture (yet, it helped little). During training, the CLIP embeddings are randomly set to zero 10% of the time, and the text caption was randomly dropped 50% of the time.
The decoder generates a 64×64 pixel image, and then two upsampling diffusion models subsequently generate 256×256 and 1024×1024 images, the former with 700M parameters, and the latter with 300M parameters. To improve upsampling robustness, the conditioning images are slightly corrupted during training. For the first upsampling stage, gaussian blur was used, and for the second, a more diverse BSR degradation is used, which includes JPEG compression artifacts, camera sensor noise, bilinear and bicubic interpolations, Gaussian noise. The models are trained on random crops of images that are one-fourth the target size. Text conditioning is not used for the upsampling models.
The prior produces image embeddings from text descriptions. The authors explored two different model classes for the prior model: Autoregressive (AR) prior and Diffusion prior. Both prior models have 1B parameters.
In the AR prior, the CLIP image embedding is converted into a sequence of discrete codes and predicted autoregressively conditioned on the caption. In the diffusion prior the continuous embedding vector is directly modeled using a Gaussian diffusion model conditioned on the caption.
In addition to the caption, the prior model can be conditioned on the CLIP text embedding since it is a deterministic function of the caption. To improve sample quality, the authors also enabled sampling using classifier-free guidance for both the AR and diffusion prior by randomly dropping this text conditioning information 10% of the time during training.
For the AR prior, the dimensionality of the CLIP image embeddings was reduced by Principal Component Analysis (PCA). 319 principal components out of 1024 keep more than 99% information. Each dimension is quantized into 1024 buckets. Authors condition the AR prior on the text caption and the CLIP text embedding by encoding them as a prefix to the sequence. Additionally, they prepend a token indicating the (quantized) dot product between the text embedding and image embedding. This allowed conditioning of the model on a higher dot product since higher text-image dot products correspond to captions that better describe the image. The dot product was sampled from the top half of the distribution. The resulting sequence is predicted using a Transformer model with a causal attention mask.
For the diffusion prior, a decoder-only Transformer with a causal attention mask is trained on a sequence consisting of:
- the encoded text
- the CLIP text embedding
- an embedding for the diffusion timestep
- the noised CLIP image embedding
- a final embedding whose output from the Transformer is used to predict the unnoised CLIP image embedding.
A dot product was not used to condition the diffusion prior. Instead, to improve quality during sampling time, two samples of an image embedding were generated, and the one with a higher dot product with a text embedding was selected.
Diffusion prior outperforms the AR prior for comparable model size and reduced training compute. The diffusion prior also performs better than the AR prior in pairwise comparisons against GLIDE.

The authors also performed investigations on the importance of the prior. They tried to condition the same decoder using different signals: 1) text caption and zero CLIP embedding, 2) text caption and CLIP text embedding as if it were an image embedding, 3) text and CLIP image embedding generated by the prior. Conditioning the decoder on just the caption is clearly worst, but conditioning on text embeddings zero-shot does produce reasonable results.

When training the encoder, authors sampled from the CLIP and DALL-E datasets (approximately 650M images in total) with equal probability. When training the decoder, upsamplers, and prior, they used only the DALL-E dataset (approximately 250M images), as incorporating the noisier CLIP dataset while training the generative stack negatively impacted sample quality in their initial evaluations.
The total model size seems to be: 632M? parameters (CLIP ViT-H/16 image encoder) + 340M? (CLIP text encoder) + 1B (Diffusion prior) + 3.5B (diffusion decoder) + 1B (two diffusion upsamplers) =~ 6.5B parameters (if I didn’t mistake anywhere).
unCLIP applications
The proposed approach allows generating images based on text descriptions. Yet, some other interesting applications are possible.

Each image x can be encoded into a bipartite latent representation (z_i, x_T) that is sufficient for the decoder to produce an accurate reconstruction. The latent z_i is a CLIP image embedding, and it describes the aspects of the
image that are recognized by CLIP. The latent x_T is obtained by applying DDIM (denoising diffusion implicit model) inversion to x using the decoder while conditioning on z_i. In other words, it is a starting noise for the diffusion process when it generates the image x (or equivalently x_0, see the denoising diffusion model scheme in the GLIDE section).
This bipartite representation enables three interesting kinds of manipulations.
First, you can create image variations for the given bipartite latent representation (z_i, x_T) by sampling in the decoder using DDIM with η > 0. With η = 0, the decoder becomes deterministic and will reconstruct the given image x. The larger the η parameter, the larger variations, and we can see what information was captured in the CLIP image embedding and present in all samples.

Second, you can make interpolations between images x1 and x2. In order to do it, you have to take CLIP image embeddings z_i1 and z_i2, then apply slerp (Spherical Linear Interpolation) to obtain intermediate CLIP image representations. There are two options for the corresponding intermediate DDIM latent x_Ti: 1) interpolate between x_T1 and x_T2 with slerp, 2) fix the DDIM latent to a randomly-sampled value for all interpolates in the
trajectory (and you can generate an infinite number of trajectories this way). The following images were generated with the second option.

Finally, the third thing is language-guided image manipulations or text diffs. In order to modify the image to reflect a new text description y, you first obtain its CLIP text embedding z_t, as well as the CLIP text embedding z_t0
of a caption describing the current image (which might be a dummy caption like “a photo” or an empty caption at all). Then you compute a text diff vector z_d = norm(z_t − z_t0). Then you rotate between the image CLIP embedding z_i and the text diff vector z_d with slerp and generate images with the fixed base DDIM noise x_T throughout the entire trajectory.

The authors also did a series of experiments for probing the CLIP latent space. Previous studies have shown that CLIP is susceptible to typographic attacks. In these attacks, a piece of text is overlayed on top of an object, which causes CLIP to predict the object described by the text rather than the object depicted in the image (remember the apple with an “iPod” banner?). Now the authors tried to generate variations of such images and found that despite a very low probability of correct classification for an image, the generated variations are correct with high probabilities. And the model never produced pictures of iPods, despite the very high relative predicted probability of this caption.

Another interesting experiment is to reconstruct images with a progressively increasing number of principal components. In the following figure, they took
the CLIP image embeddings of a handful of source images and reconstruct them with progressively more PCA dimensions, and then visualize the reconstructed image embeddings using the decoder with DDIM on a
fixed seed. This allows seeing what semantic information the different dimensions encode.

Remember also the struggles unCLIP has with attribute binding, text generation, and details in complex scenes.
The first two problems are probably due to CLIP embeddings properties.
The attribute binding problem might happen because the CLIP embedding itself does not explicitly bind attributes to objects, so the decoder mix up attributes and objects when generating an image.

The text generation problem is probably because the CLIP embedding does
not precisely encode the spelling information of a rendered text.
The low details problem might emerge due to the decoder hierarchy producing an image at a base resolution of 64×64 and then upsampling it. So, with a higher base resolution, the problem might disappear (at the cost of additional training and inference compute).
So, you’ve seen the evolution of the text-based image generation models by OpenAI. Other companies work in this field as well, and we might have separate posts on it in the future.

DALL·E 2 (or unCLIP) is a huge improvement over the first version of the system, DALL·E 1, made in just one year. However, there is still much room for improvement, and we are waiting for the next breakthroughs.
It’s a pity that these powerful and interesting models are kept closed. I’d like to see more such models being published or at least provided via an API. Otherwise, all these benefits are for some very limited audiences.
I understand that such models might have biases, sometimes produce not the right types of content, or be used by malicious agents. We have to understand how to deal with all these things. Yet there are myriads of potentially good uses, and such decisions block them.
I hope DALL·E 2 (or another similar model) will be generally available through an API soon.
